Audiences
This tab is available if at least one of the collaboration types Remarketing audiences, AI lookalike audiences, or Rule-based audiences is enabled in the Media DCR and you have at least one of the Create audiences or Export audiences permissions.
As soon as both, seed and base audiences, have been provided, the audience creation is prepared. This may take up to several hours, depending on the data size. Once completed, the audiences tab is accessible.
Creating audiences
To create audiences, you need the Create audiences permission.
To create an audience, see the steps below. Once an audience has been created, it is added to the audience list with status Computing. Once the computation of the audience has finished, the status changes to Ready.
Each audience in the list shows both the number of users (matched on userId) and the number of activation IDs. The activation ID count uses the activation ID currently selected by the base audience provider.
First click on Create new audience, then choose the desired audience type and see the sections below.
Creating a remarketing audience
Select Remarketing audiences, then choose the seed audience you wish to re-engage. Each remarketing audience contains the users that overlap between the selected seed audience and the base audience.

Creating a rule-based audience
Choose Rule-based audience, then combine or filter existing audiences and attributes to define the rule set.
You can craft an audience by applying several inclusion and exclusion criteria against the publisher data (or data partner data) using segments, age, and gender information.
Examples of rule-based audiences:
- Exclusion targeting: Build an audience that excludes the seed audience, which is especially powerful for new customer acquisition campaigns
- Top-affinity segment targeting: Build an audience based on the top affinity segments identified in the audience insights dashboards

Creating an AI lookalike audience
The AI lookalike model uses machine learning to identify which users in the base audience are most similar to users in the seed audience. This provides increased reach while maintaining strict privacy guarantees since your seed audience cannot be re-identified from the lookalike audience.
- Select AI lookalike audience from the audience type options
- Choose the seed audience to model from
- Adjust the Precision vs Reach slider to balance similarity and audience size, informed by the quality score (see Technical details below)
- Optionally enable Exclude the seed audience used for training from your new audience to replace the users in the overlap with the next similar users
Selecting the audience size
The sizing of the lookalike audience depends on several factors: Most importantly the media budget and desired reach but also the audience quality score or the ROC curve, it informs if the performance of the model decreases past a certain point. Some further considerations:
- Audience quality scores should not be compared across data clean rooms, campaigns or publishers. This is a relative score, not an absolute score.
- The size of the overlap ("training dataset" in the context of the lookalike) is not required to be "huge" to reach good model performance as long as:
- The overlap is larger than the threshold of 100
- The segments provided by the base audience provider are granular enough
- Audience lookalike remains more an art than a science. Rather than building a single lookalike audience, we recommend to generate two or three (e.g. a 10% extension and a 20% extension) such that you can compare their performance and have enough campaign delivery in case the small lookalike (in this example the 10% audience) does not deliver enough.

Technical details
How it works
Training step
The lookalike model is a machine learning classifier so it requires positive/negative labels and features to get trained on. The training dataset is composed of:
Labels
- Positive labels are assigned to the base audience provider matchingIds that match with the seed audience provider matchingIds ("matched users")
- Negative labels are assigned to the base audience provider matchingIds that did not match with the seed audience provider ("non matched users"). Only a sample of negative labels are included to reach a target ratio of positive / negative label to 1:1.
Features
The model features are the segment names from the base audience provider for all matchingIds (positive and negative labels).
Before training the XGBoost classifier, Decentriq randomly split the prepared dataset into training and test sets (90% training, 10% test).
The training step can only be completed if these two conditions are met:
- There is a minimum of 100 matched users (so 90 positive labels in the training dataset). The total number of positive labels available for training is displayed in the UI and is called "Seed audience for model training"

- There is a minimum of 10 and a maximum of 2000 segment names provided by the base audience provider
Testing step
After the model training is completed, the lookalike model performance is evaluated on the test dataset. Decentriq displays the corresponding ROC curve and audience quality score.
ROC curve
The ROC curve indicates how the model performs:
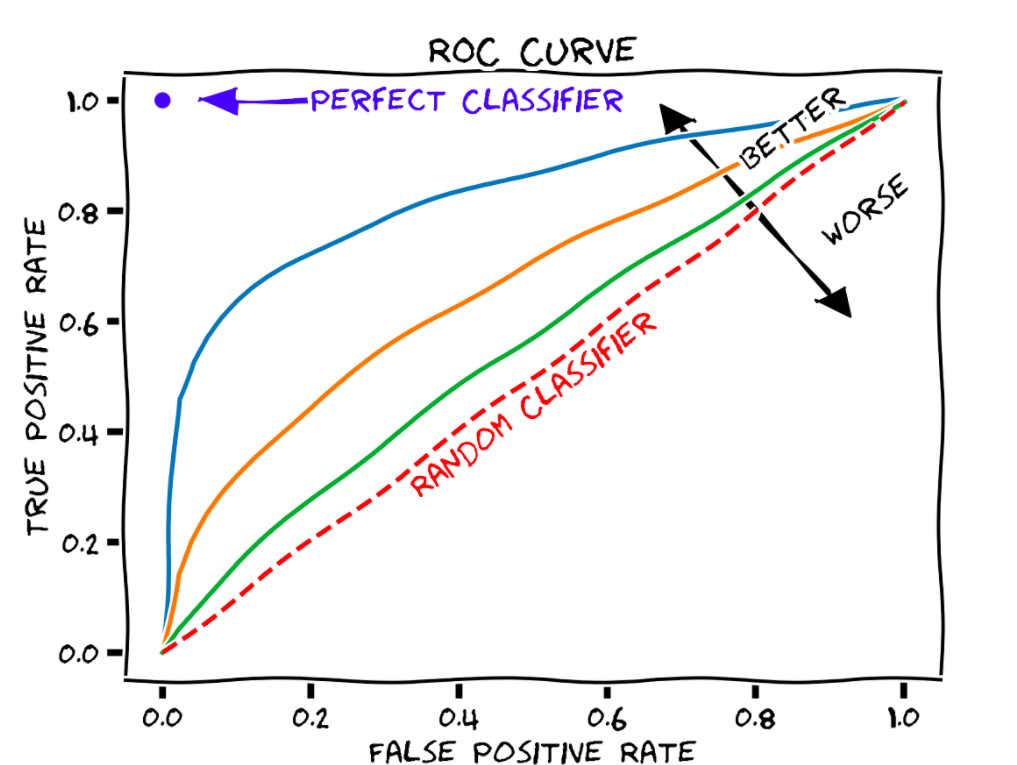
- Straight line - no performance: A ROC curve with a straight line means that the model is as good as selecting users randomly. It's obviously not the desired outcome
- Concave line - positive performance: A ROC curve with a concave line means that the model outperforms a random selection. The more the curve is concave (far from the straight line), the more the model performs
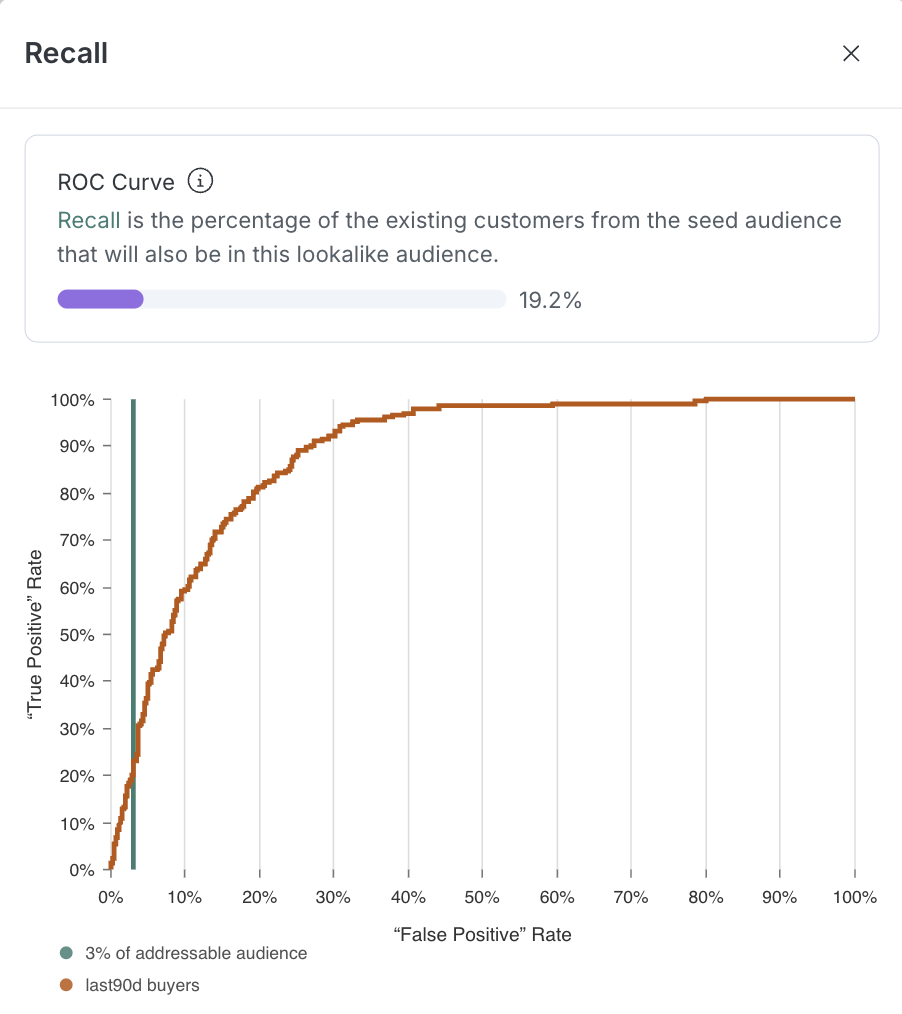
Recall is the percentage of the existing customers from the seed audience that will also be in this lookalike audience. Use the slider to see how recall changes as you adjust the precision/reach threshold.
Audience quality score
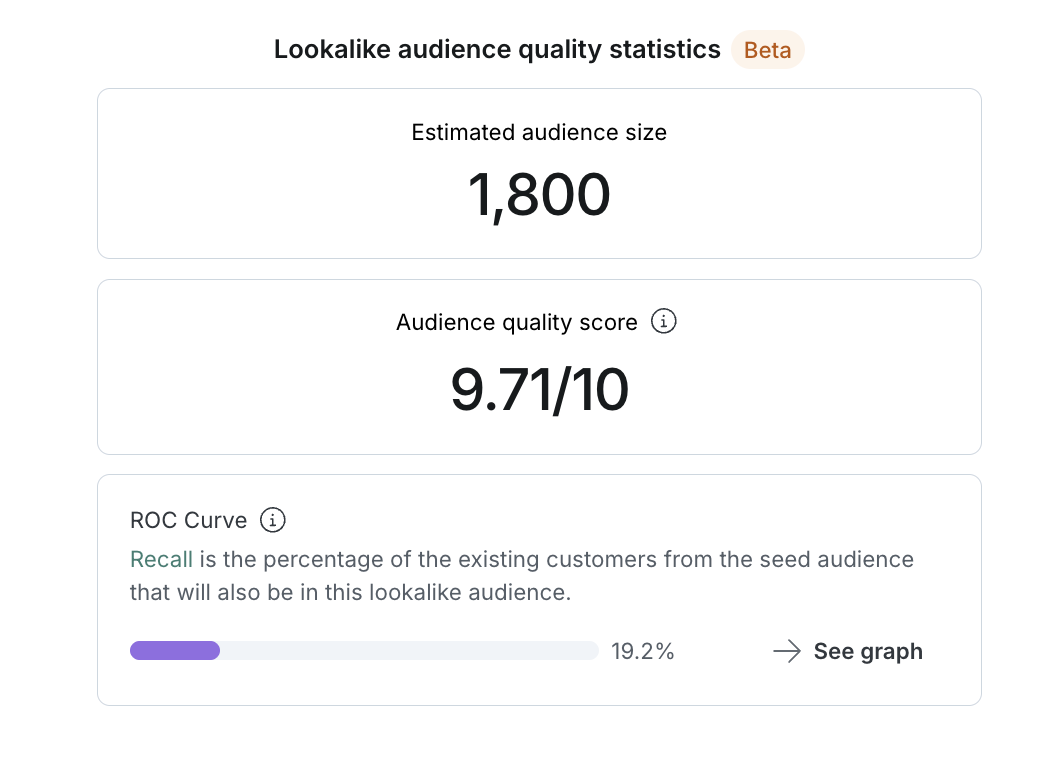
The higher the score is, the better the audience is expected to perform.
Inference step
Decentriq runs inference on all the userIds from the base audience provider that have associated segments in order to generate a score between 0 and 1. The higher the score is, the more similar a base audience provider user is from the seed audience provider users.
Audience sizing
Decentriq sorts these users by decreasing score. The user interface allows the user to select a percentage subset from these ranked users.
Optionally the user can exclude the matched users between the seed audience and base audience from the resulting lookalike audience.
Combining lookalikes and rule-based audiences
You can generate a lookalike audience and then use it as input of the rule-based audience builder to apply further inclusion or exclusion criteria. For example, excluding an entire age group from the lookalike audience.
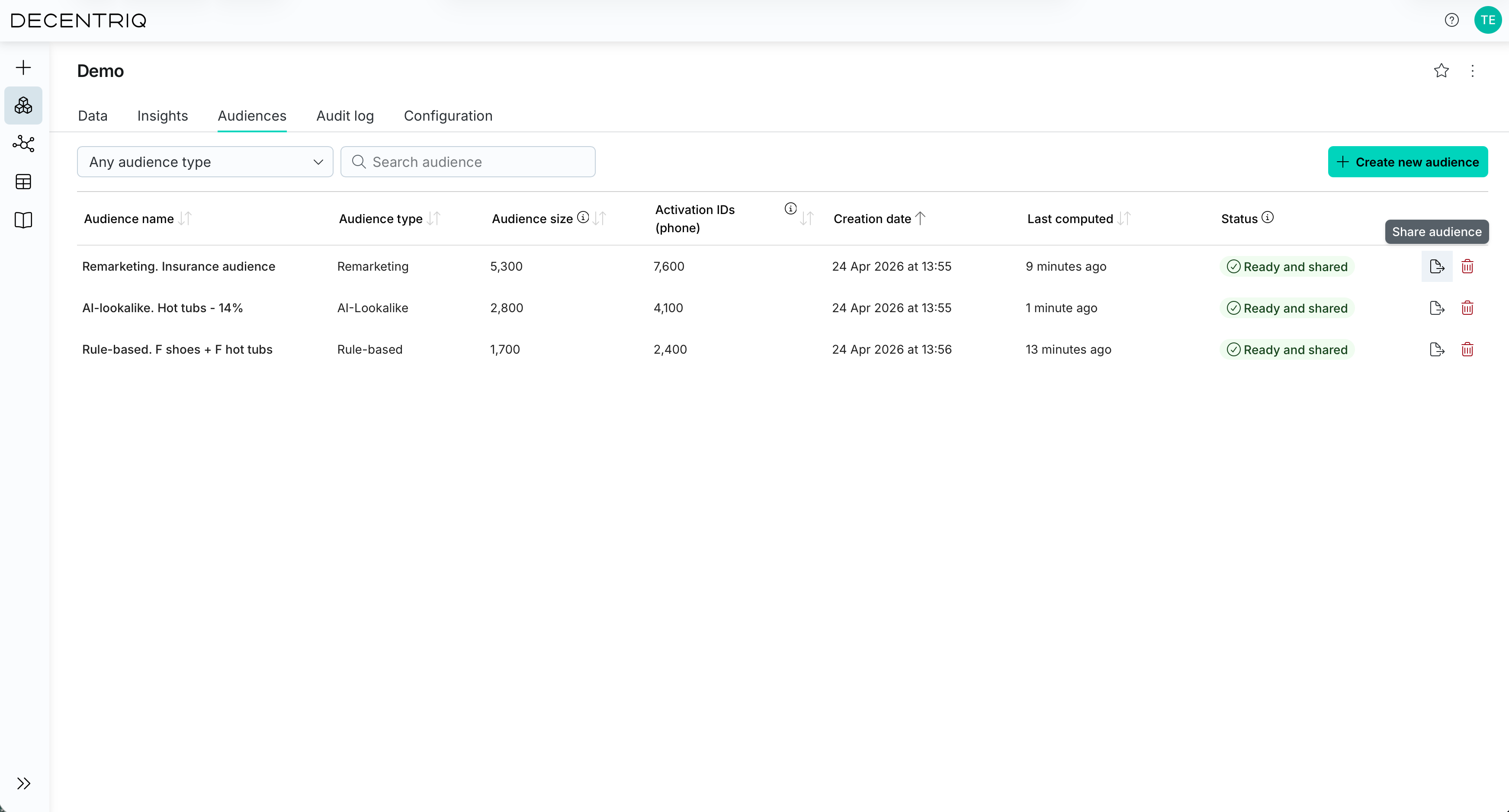
Collaborating on audiences
To collaborate with other participants on audiences, click on the Share button of a specific audience. The participants you share an audience with can then create additional audiences based on the shared one (if they have the Create audiences permission) or export it (if they have the Export audiences permission).
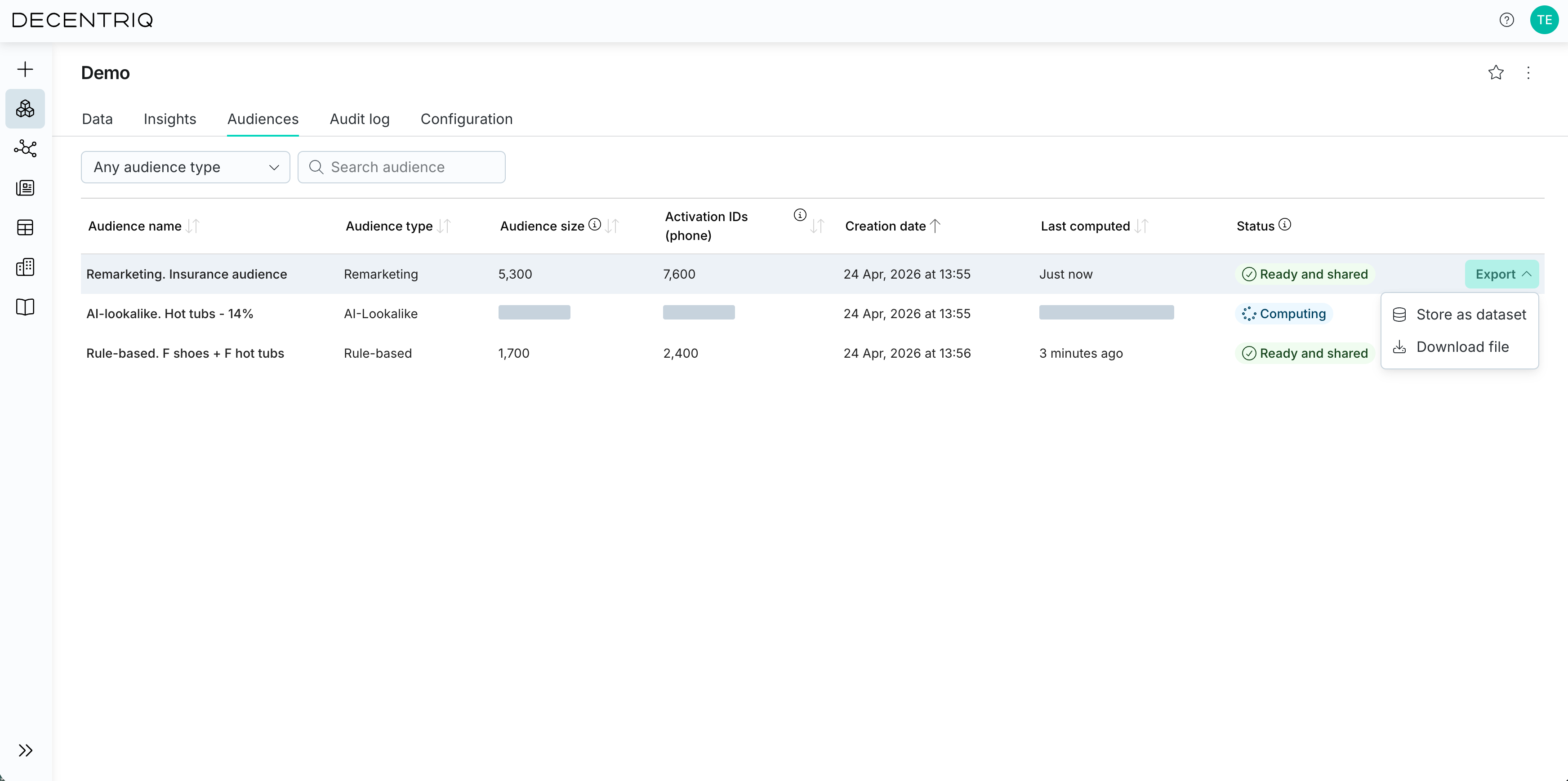
Exporting audiences
To export audiences, you need the Export audiences permission.
To export an audience, click Export (right-hand column) and choose to download or store in your datasets from which it can then be exported to external platforms.
The exported audience contains the activation ID currently selected by the base audience provider, formatted as a single-column CSV without headers. To export under a different activation ID, the base audience provider switches the selected activation ID. All subsequent exports are in terms of the new activation ID.